Over the end-of-year slowdown and the holidays, I’ve started to learn something new: React Native (and TypeScript along with it). It’s refreshing to approach a technology I haven’t actively used with a beginner’s mindset. Plus, it’s fun to build stuff.
A new tech stack for me: React Native and TypeScript
React Native is a framework to build mobile apps for both iOS and Android using the same codebase (which is either JavaScript or TypeScript).
You can do much more with React Native, but this is what it’s mostly used for.
Why React Native?
First, professional relevance: I work as an AI and Machine Learning Engineer, so I usually work in the Python ecosystem. However, ML software doesn’t live in isolation and we are often building web or mobile applications, either as internal tools or for product integration of the machine learning systems. To be able to build web and mobile applications, better knowledge of React and the ecosystem makes a lot of sense to me. In fact, my whole team has recently decided to up-skill in this direction.
Second, personal interest: Since I stopped working as a web developer in 2017, I haven’t really followed the changes in the web and JS space. I’ve remained curious about web technology and have always wanted to be able to build mobile apps for my personal use and potential side projects. React Native offers both, plus a lot of the knowledge will transfer easily to vanilla React for the web.
How I am learning
I like reading traditional paper books when learning something new because I can focus better when I look at printed paper rather than a digital screen.
- Book 1: Professional React Native by Alexander Kuttig. A compact overview of the important elements of React Native projects and a collection of best practices. The book is not comprehensive in listing the available API methods, but I like this style: It’s a fast-paced guide that I can use to start building my own projects. The book has many pointers on important packages. There are some mistakes in the code listings and the code formatting is sometimes broken, so the whole thing feels a little rushed. Still, I’d recommend it if you have previous programming experience.
- Book 2: Learning TypeScript by Josh Goldberg. A compact, but detailed look at the TypeScript language. I have only covered the basics of the language to get me started on my own projects, but I will continue reading this book because I want to make use of the full power of TypeScript in my projects. It’s very well explained and has clearly gone through a better editing process than Book 1 (which is what I would expect from an O’Reilly publication). Clear recommendation.
- Learning by doing: As I am working through these books (and googling anything I don’t know), I am building my first project, see below.

My first project: A Mastodon client
Having looked at the Mastodon API in a previous (Python) project, I decided to build a Mastodon mobile app for my personal use – or rather my learning experience.
I have worked on the project for a few days now, and it is almost at MVP-level, meaning it provides some value to the user (i.e. to me).
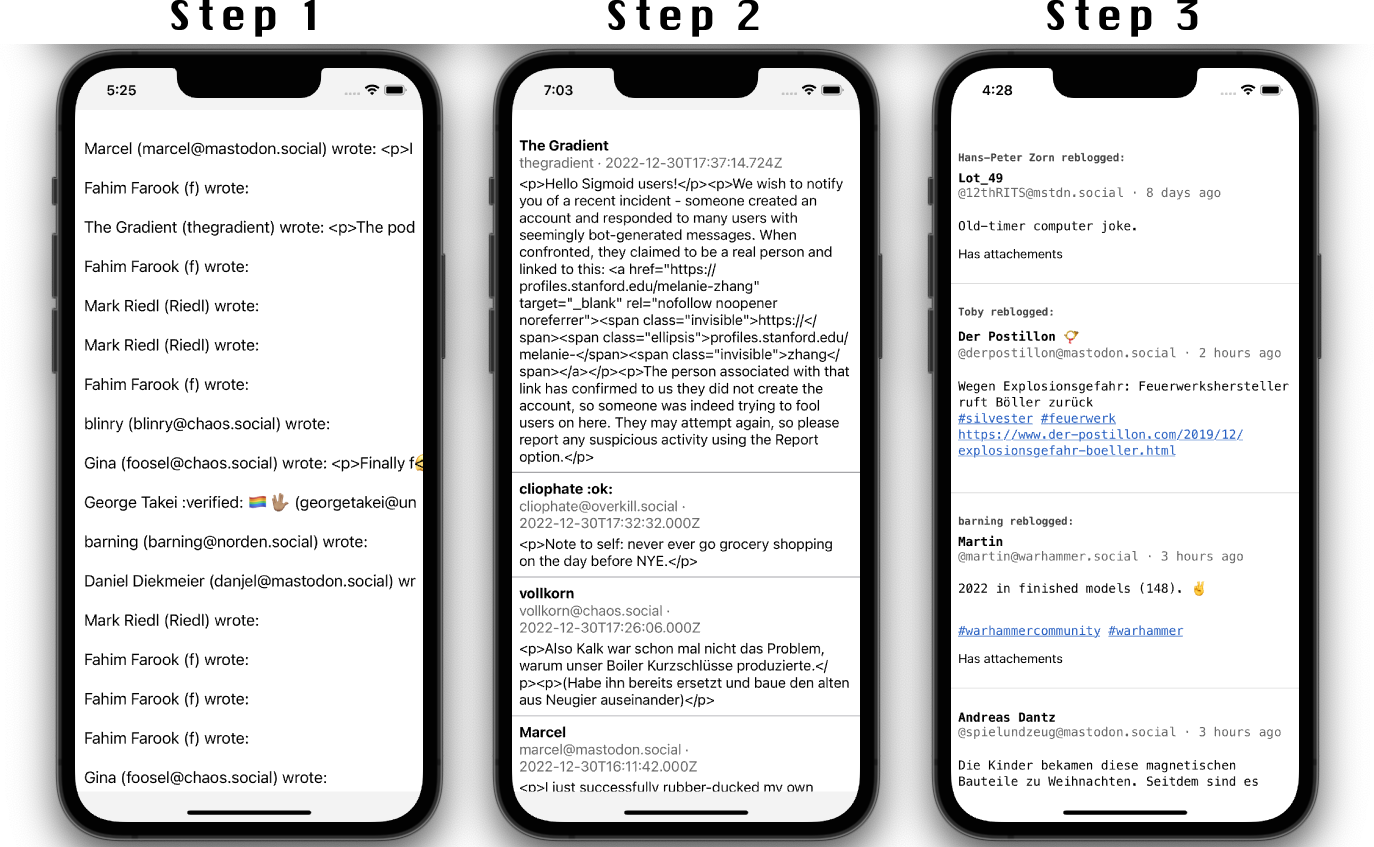
What I’ve implemented and learned so far:
Project setup of a React Native app
This took longer than expected because I needed to update Node and Ruby versions on my Mac. This reminded me of the frustration I felt as a web developer 5+ years ago when every few weeks the community moved to a new build tool and all dependencies had to remain compatible. It took me around 2 hours for the setup, but I’m happy I came out on the other side because since then the dev experience with React Native and hot-reloading of the app in the phone simulator has been pleasant.
Fetching the personal home timeline
I decided not to use any Mastodon API wrappers but to use the REST API directly. It helps me learn what’s actually going on. This is straightforward using fetch() and casting the result to a matching type definition in TypeScript. Reading the home timeline requires authentication. I haven’t built a UI-based login flow yet, but I am simply passing the auth token associated with my Mastodon account.
Display of the home timeline
This is the only real feature I’ve implemented, but it helped me to learn quite a bit:
- Build and structure React components
- Use React hooks
- Styling of React Native views
- How to render the HTML content of the posts as native views
- How to implement pull-to-refresh and infinite scrolling of a list view
What is still missing
For a full-fledged Mastodon client, I’ve maybe implemented 2% and the remaining 98% is still missing. Even for an MVP “read-only” app, I am still missing some crucial pieces:
- Login flow
- Display attachments (images, videos, …)
- Detail view of the toots with more details (replies, like count, …)
I need to learn a few more core concepts to be able to implement these features, most notably navigation of multiple views and storing data on the device.
My plan is to build out this MVP version to continue learning the core concepts.
Afterwards, I will probably look for another project idea, one that is uniquely “my project”.
Ambitious ideas for this project
If I do end up working on the Mastodon app longer term, there are some ideas that would be fun to implement. In particular, I’d love to bring some of my Data Science / ML experience over to a mobile app. How about these ideas:
- Detect the language of posts and split your timeline into localized versions
- Detect the sentiment of posts and let the app know if you want to filter out clickbaity posts today
- Summarize today’s posts in a short text (possible GPT3/ChatGPT integration)
- Cluster posts into topics (like “news”, “meme”, “personal” or “cat content”) so that you can decide if you’re in the mood to explore or simply want to focus on what’s relevant today
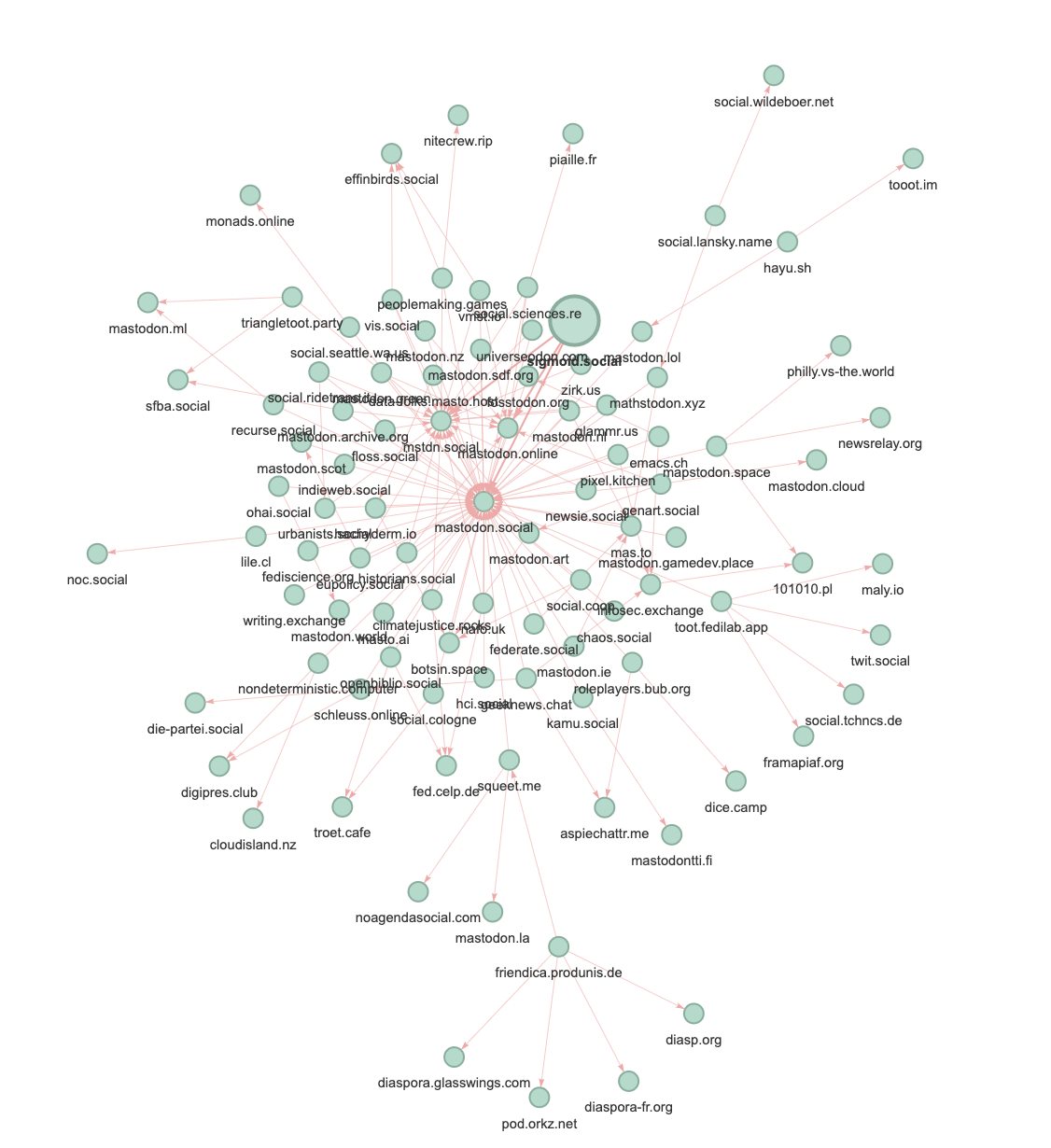
- Include tools to explore your Mastodon instance or the whole fediverse: Find accounts you would like, and find accounts that are popular outside your own circles. Some inspiration is in my previous post on exploring the Fediverse.
Follow along
If you want to follow along, you can find my current project progress on Github. Remember that this isn’t meant as an actual Mastodon client, but as an educational exercise for myself. Use at your own risk.
Github for the project source: https://github.com/floriandotpy/rn-mastodon