For a few years now, I have been a regular attendant of the Chaos Communication Congress, this year called #38C3. But this congress is more fun when you bring your own project instead of only attending talks.
The idea: Let’s build a cyber oracle: A small machine for visitors to collect a prophecy in the style of a cyber punk fortune cookie. In 2024, we should be able to run a LLM (large-ish language model) on a small computer and let it do it’s thing, right? As it turns out: Yes, pretty much.
Who worked on the project: Mainly Pablo (hardware) and myself (software). We received help from Kim (3d-printed case) and Markus (last minute debugging and bug fixing).
Brainstorming possible directions

Thanks for the concept art to Leonardo.ai, but we needed to build something more pragmatic and in about a week’s time. So instead of an ambitious cyber punk robot, we took a simpler path.
The hardware
Pablo took ownership of researching, purchasing and assembling all hardware components, as well as figuring out how to work with the cheap printer from a Python script. Parts needed:
- Raspberry Pi 5
- Raspberry Pi Touch Display 2
- Thermal printer (Amazon link) along with some paper (Amazon link)
- A fitting power supply
- A custom case, aptly sized for the printer and display. Luckily, Kim volunteered to design and 3d-print the enclosure. He has also published the case on Makerworld.

Building a cyber-ish UI for the touch screen
While Pablo and Kim handled hardware and the case, I took care of building the software. First, the UI. Usable on a touch screen and with the option to pick one out of nine “cyber zodiacs”, imagined based on common tropes and terms in the German hacker community.
The tech stack is plain: A local Python web server using FastAPI and a frontend built using some CSS and some JavaScript (no frameworks were harmed in the making of the project).
For the generation of the prophecies (i.e. the fortune messages), the backend was busy for about 30 seconds (more on the step in the next section).
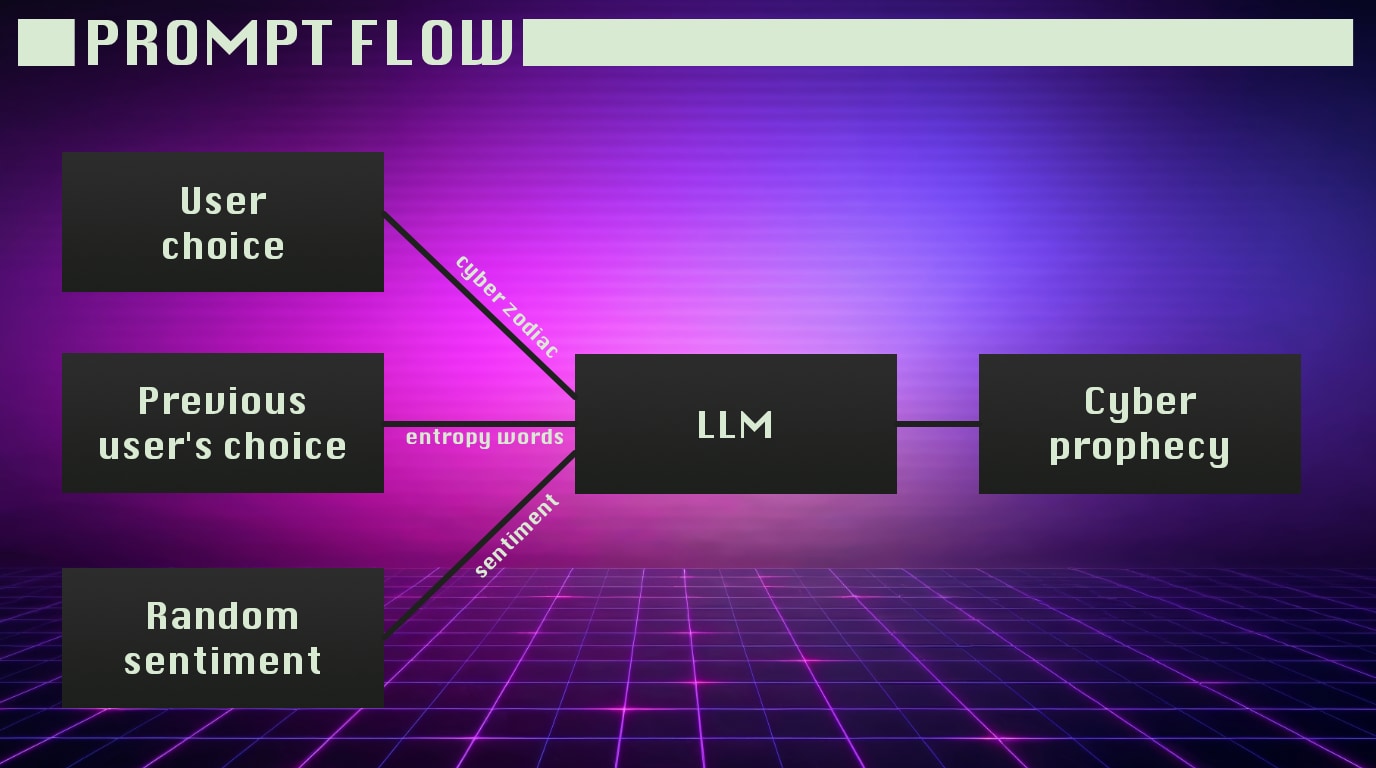
Keeping the user waiting for 30 seconds felt broken, so we added a second step in the UI, simply to bridge the waiting period: While the machine is already doing its thing in the background, the user can select additional terms to leave as “entropy” for the person that is using the cyber oracle after them. Born out of necessesity, this “feature” actually made a lot of sense, because it connected each visitor of our machine to the person who came before, and the one who came after.

Generating prophecies
The core of the cyber oracle was a small LLM (that is, a small large language model, so maybe a… language model?). I did some research and picked Gemma 2 in the 2B variant. It runs super fast on my macbook and produces decent results, and it runs reasonably fast on the Raspberri Pi 5.
I was impressed by that. We’ve come a long way in the last two years!
Pablo and I hand-crafted nine prompts for the different zodiacs the user could pick. The results were super fun. To increase variation, we enriched the prompt with the “entropy words” picked by the previous user and in fact, across 900+ generated prophecies, we had a lot of different versions and I never noticed an exact duplicate.
One additional input was a sentiment (optimistic, neutral, dire, and so on) to achieve a variation in tone across the various prophecies.
Here’s a typical prompt (the full prompt generation logic is on Github).
You are a fortune teller in a cyberpunk story.
Write a fortune cookie message for the cyber
zodiac "Cryptogeek" with a sentiment of "neutral".
The message should be exactly 2 lines long.
Write in German. Do not explain your answer.
Be short and concise. Add no special characters.
The following terms and phrases are typical for
the cyber zodiac Cryptogeek. Use them as inspiration
for the message but don't just copy them verbatim:
- Public Key
- Private Key
- Alles verschlüsseln
- Blockchain
- Keysigning Party
- GPG Key
- https everywhere
- Private Daten schützen, öffentliche Daten nützen
One artifact of using a small model like Gemma2 2B in a non-English language (i.e. German): Some phrases came out a little off and stilted. Ironically, this went really well with the idea of a text from a fortune cookie, so we didn’t even bother improving this part.
This is what the finished project looked like
And here’s what it looked like in the end.


Some prophecies
See the images for some examples from the congress. You can also see all of them on Mastodon, because the script published each one as it was printing it.


Hackers loved it
The little machine attracted a lot of attention and we had close to a thousand prophecies printed over the course of 4 days. The hacker community is naturally very sceptical about “AI”. But local inference (“look mum, no cloud!”) and completely pointless output just for the fun of it seemed to warm people’s heart to the curious little box.
Below are some stats about the usage and the most popular zodiacs.
| Total printed | 995 fortunes |
| Most popular zodiac | “Einhorn” (Unicorn): 203 fortunes |
| Least popular zodiac | “Cryptogeek”: 41 fortunes |
| Shortest fortune (30 characters): | “Alles verschlüsseln. Saal 1.” |
| Longest fortune (268 characters) | “Mit deinem Einhorn-Glitzer wird deine magische kreative Energie in Freifunk-Chaos zu einem wundervollen Regenbogen transformiert. Liebe und Freundschaft verbinden dich mit deiner digitalen Gemeinschaft, während du deine Kreativität mit 5G-Technologie verwirklichst.” |
Build your own oracle using our source code
This was a fun and not-so-serious little AI project completed in about 3 or 4 evenings of work. The code is messy, but that’s in the spirit of projects like these.
When (if) we bring the oracle to the event next year, I hope to clean up the front-end code and add some more gimmicks in the prompts. Find the project on Github and let us know if you use it to build a similar little machine!